사내에서 사용하는 데이터 분석 툴의 지도 객체에 멀티 폴리곤 형식의 데이터를 매핑하는 작업을 진행했다.
멀티폴리곤은 좌표 데이터의 연속적인 집합을 의미한다. 멀티폴리곤을 통해 지역을 도형으로 감싸 각 지역의 특성을 한눈에 보기 쉽게 해준다. 멀티폴리곤은 좌표의 집합인데, 좌표는 말 그대로 점 하나만 찍으면 되기 때문에 데이터 로딩 속도가 빠르지만 멀티폴리곤은 수많은 좌표의 집합이므로 데이터의 스케일이 커져서 첫 로딩 시에 많은 시간이 소요된다.
이 수많은, 촘촘한 멀티폴리곤의 좌표 데이터를 일정하게 생략시켜 좌표의 개수를 줄인다면 로딩 속도가 늘어나지 않을까 해서 simplication작업을 해보았다.
먼저, 폴리곤 데이터가 필요해서 아래 블로그에서 받았다.
[공간자료] 통계청 데이터 join용 시군구 shp파일 공유
안녕하세요, 오늘은 시군구 shp 파일을 공유합니다. 홍시는 이번에 수강하는 과목 중에서 공간자료 + 통계자료를 함께 써야 하는 수업이 있는데요, 통계청에서 제공하는 통계데이터의 시군구 단
kimhongsi.tistory.com
위 블로그에서 여러가지 경계 shp 파일을 제공해주는데, 눈에 띄는 차이점을 확인하기 위해 경계가 많이 쪼개져있는 시군구 데이터를 사용했다.
import json
import pandas as pd
import geopandas as gpd
def convert_shp(file: str) -> str:
geojson = gpd.read_file(file, encoding='utf-8') # shp 파일 읽기
geojson = geojson.to_crs(epsg=4326)
print("GEOJSON2", geojson)
geojson = geojson.to_json() # shp to json
return geojson
def convert_from_geo_to_dataframe(geojson: gpd.geodataframe.GeoDataFrame):
plg = json.loads(geojson)
plg = plg["features"]
df = pd.DataFrame(columns=["sig_cd", "sig_kor_nm", "geometry"])
for p in plg:
geometry = p["geometry"]
properties = p["properties"]
sig_cd = properties["code"]
sig_kor_nm = properties["SIGUNGU_NM"]
df.loc[len(df)] = [sig_cd, sig_kor_nm, geometry]
df.set_index(df.columns[0])
print(df["geometry"])
return df
def print_json(df: pd.DataFrame):
print(df.iloc[10])
def save_csv(df: pd.DataFrame):
df.to_csv("./kor_stat_sigungu.csv")
if __name__ == "__main__":
file = "./SGG_kostat/SGG_kostat_인코딩해결.shp"
geojson = convert_shp(file)
df = convert_from_geo_to_dataframe(geojson)
save_csv(df)shp 파일을 먼저, 프롬프트에서 확인하고 전처리 후에 csv 형태로 db import 하기 위해서 pandas를 함께 사용했다.
파이썬에서는 geojson 형태의 데이터를 다루기 위해 geopandas라는 라이브러리를 사용할 수 있다.
해당 라이브러리를 통해 한국에서 자주 사용하는 EPSG 4326 좌표계의 형태로 변경했다.
또한, 사내에서 사용하는 좌표계는 경위도가 아닌, 위경도의 형태로 사용하기 때문에 다운로드 받은 파일의 좌표 순서를 변경해야 했다. geopandas에서 따로 변경시켜주는 메소드는 제공하지 않아 어떻게 할지 고민하다가 정규식으로 처리했다.
def swap_geometry(text: str) -> str:
new_text = re.sub(r'\[([\d+\.]+),\s*([\d+\.]+)\]', r'[\2, \1]', text)
return new_text
전처리를 통해 생성된 csv를 데이터베이스에 넣어 지도 객체를 로드해보았다.

전체 데이터를 불러오는데 총 1.3분이 소요됐으며, 248MB의 데이터를 요청했다. 사용자에게 시각화 서비스를 하는데 1.3분이면 사용자가 떠나기에는 충분하고도 남고 또 남는 시간이기 때문에, 아주 치명적인 시간이다. 이제 파이썬의 geopandas 라이브러리를 사용하여 단순화 작업을 해보자.
위에서 shp 파일의 csv 변환을 위해 geopandas 를 사용했다.
geopandas 를 사용하기 위해서는 먼저 설치가 필요하다. 설치는 pip나 poetry를 사용하여 진행할 수 있다.
(geo) PS D:\EPIS\epis\geo\Scripts> pip install geopandas
Collecting geopandas
Downloading geopandas-0.10.2-py2.py3-none-any.whl (1.0 MB)
|████████████████████████████████| 1.0 MB 1.7 MB/s
Collecting pyproj>=2.2.0
Downloading pyproj-3.2.1-cp37-cp37m-win_amd64.whl (6.2 MB)
|████████████████████████████████| 6.2 MB 3.3 MB/s
Collecting shapely>=1.6
Downloading shapely-2.0.1-cp37-cp37m-win_amd64.whl (1.4 MB)
|████████████████████████████████| 1.4 MB 1.6 MB/s
Collecting fiona>=1.8
Downloading Fiona-1.9.3-cp37-cp37m-win_amd64.whl (22.0 MB)
|████████████████████████████████| 22.0 MB 6.4 MB/s
Requirement already satisfied: pandas>=0.25.0 in d:\epis\epis\geo\lib\site-packages (from geopandas) (1.3.5)
Collecting certifi
Using cached certifi-2022.12.7-py3-none-any.whl (155 kB)
Requirement already satisfied: numpy>=1.14 in d:\epis\epis\geo\lib\site-packages (from shapely>=1.6->geopandas) (1.21.6)
Collecting importlib-metadata; python_version < "3.10"
Using cached importlib_metadata-6.6.0-py3-none-any.whl (22 kB)
Collecting attrs>=19.2.0
Downloading attrs-23.1.0-py3-none-any.whl (61 kB)
|████████████████████████████████| 61 kB 1.9 MB/s
Collecting click~=8.0
Using cached click-8.1.3-py3-none-any.whl (96 kB)
Collecting cligj>=0.5
Downloading cligj-0.7.2-py3-none-any.whl (7.1 kB)
Collecting click-plugins>=1.0
Downloading click_plugins-1.1.1-py2.py3-none-any.whl (7.5 kB)
Collecting munch>=2.3.2
Downloading munch-2.5.0-py2.py3-none-any.whl (10 kB)
Requirement already satisfied: pytz>=2017.3 in d:\epis\epis\geo\lib\site-packages (from pandas>=0.25.0->geopandas) (2023.3)
Requirement already satisfied: python-dateutil>=2.7.3 in d:\epis\epis\geo\lib\site-packages (from pandas>=0.25.0->geopandas) (2.8.2)
Collecting zipp>=0.5
Collecting colorama; platform_system == "Windows"
Using cached colorama-0.4.6-py2.py3-none-any.whl (25 kB)
Requirement already satisfied: six in d:\epis\epis\geo\lib\site-packages (from munch>=2.3.2->fiona>=1.8->geopandas) (1.16.0)
Installing collected packages: certifi, pyproj, shapely, zipp, typing-extensions, importlib-metadata, attrs, colorama, click, cligj, click-plugins, munch, fiona, geop
Successfully installed attrs-23.1.0 certifi-2022.12.7 click-8.1.3 click-plugins-1.1.1 cligj-0.7.2 colorama-0.4.6 fiona-1.9.3 geopandas-0.10.2 importlib-metadata-6.6.0
단순화는 아주 간단하게 해결할 수 있다. geopandas에서 simplify라는 메서드를 제공한다.
메서드에서 사용하는 파라미터를 살펴보자.

1) tolerance
단어 의미 그대로, 허용 오차를 말한다. 허용 오차란 원본 geometry와 변경된 geometry 간의 최대 오차 거리를 뜻한다.
예를 들어, 미터 단위의 좌표 시스템에서 tolerance를 100으로 지정해주면 실제로 100m 간격으로 좌표를 축약한다는 의미이다. 다시 말해 tolerance의 크기를 키울수록, 더 단순화된 결과를 반환한다.
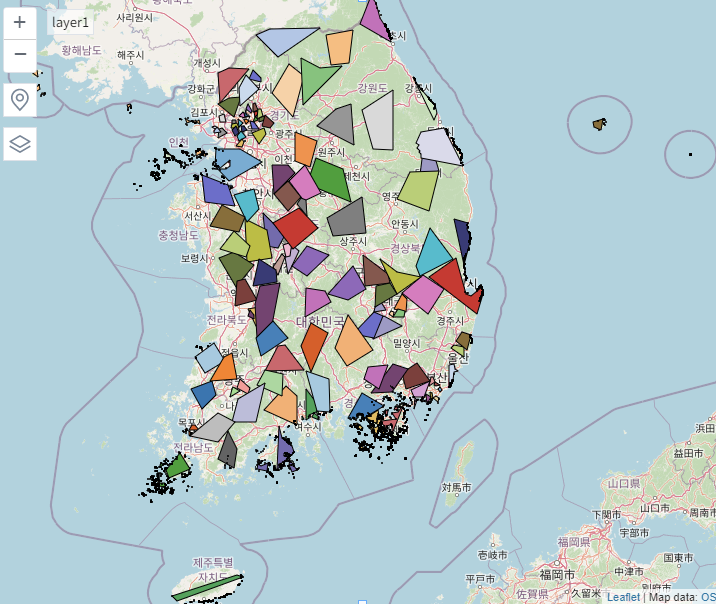
tolerance 값을 너무 크게 주면 뭉개져버리기 때문에 적당히 부여한다.
2) preserve_topology
불리언 타입의 파라미터, 이 파라미터는 빠른 알고리즘을 사용할 것인가에 대해 설명한다. preserve_topology 값을 false로 두면, 더 빠른 알고리즘을 사용하지만, 결과값의 유효성은 보장하지 않는다.
simplify 메서드를 이용한 간단한 함수 하나를 구현한다.
def simplification(geojson: gpd) -> gpd:
geojson["geometry"] = geojson["geometry"].simplify(
tolerance=100, preserve_topology=True
)
return geojson위 함수를 shp파일을 전처리한 부분에 넣어주면 단순화를 간단하게 진행할 수 있다.
단순화한 파일을 다시 로딩해보면..
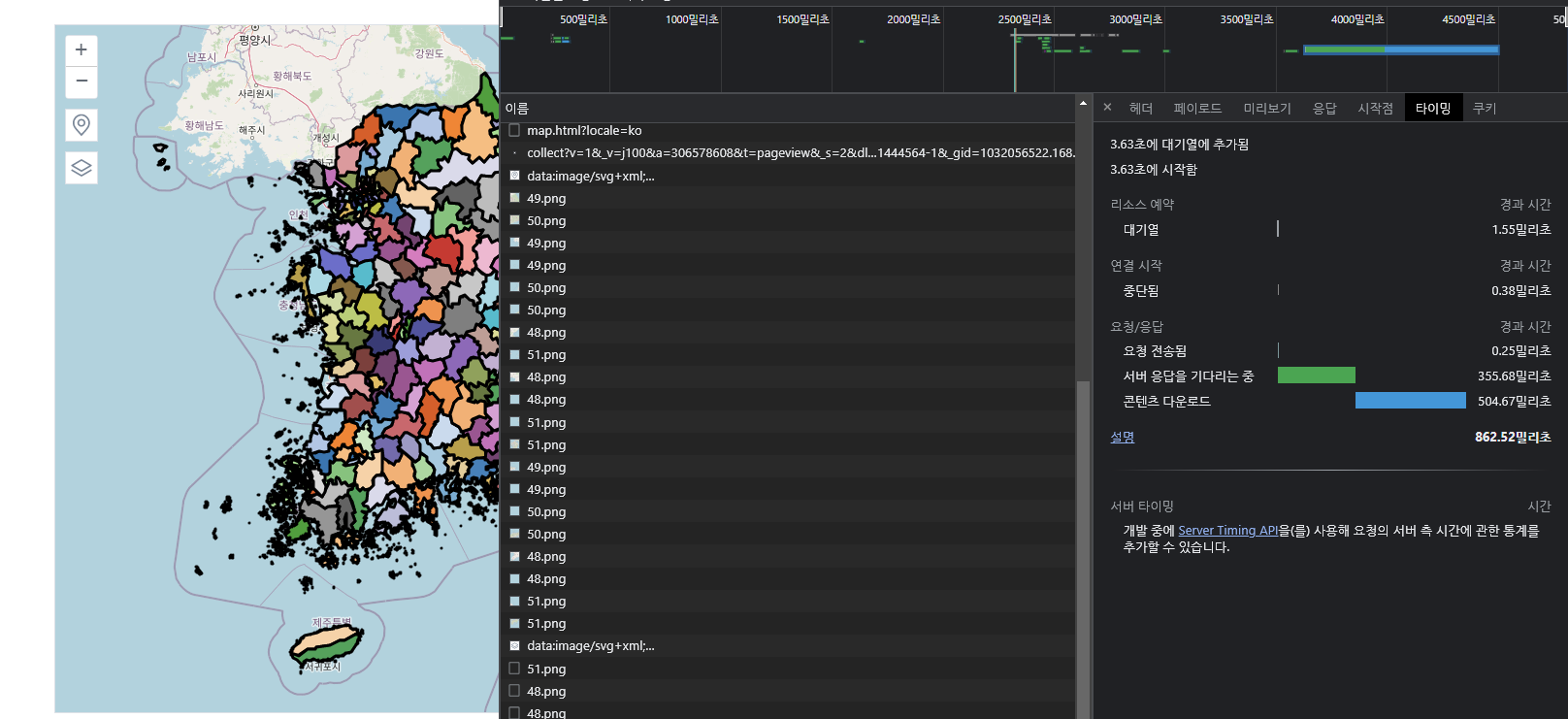
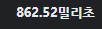
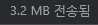
로딩시간은 약 862밀리초, 리소스는 3.2MB로 시간으로는 약 90배, 리소스는 약 80배 정도 성능 향상을 볼 수 있었다.
전체코드는 다음과 같다.
import json
import re
import pandas as pd
import geopandas as gpd
def convert_shp(file: str) -> str:
geojson = gpd.read_file(file, encoding="utf-8") # shp 파일 읽기
geojson = geojson.to_crs(epsg=4326)
geojson["geometry"] = geojson["geometry"].simplify(
tolerance=0.01, preserve_topology=True
) # simplification
geojson = geojson.to_json() # shp to json
return geojson
def convert_from_geo_to_dataframe(geojson: gpd.geodataframe.GeoDataFrame) -> pd.DataFrame:
plg = json.loads(geojson)
plg = plg["features"]
df = pd.DataFrame(columns=["sig_cd", "sig_kor_nm", "geometry"])
for p in plg:
geometry = p["geometry"]
properties = p["properties"]
sig_cd = properties["code"]
sig_kor_nm = properties["SIGUNGU_NM"]
df.loc[len(df)] = [sig_cd, sig_kor_nm, geometry]
df["geometry"] = df["geometry"].astype(str).apply(swap_geometry) # 경위도 순서 변경
df["geometry"] = df["geometry"].str.replace("'", '"') # json 형태 인식을 위해 더블쿼트로 변경
print_json(df)
return df
def print_json(df: pd.DataFrame):
print(df.iloc[10])
def swap_geometry(text: str) -> str:
new_text = re.sub(r"\[([\d+\.]+),\s*([\d+\.]+)\]", r"[\2, \1]", text)
return new_text
def save_csv(df: pd.DataFrame):
df.to_csv("./kor_stat_sgg_simple.csv", index=False)
if __name__ == "__main__":
file = "./SGG_kostat/SGG_kostat_인코딩해결.shp"
geojson = convert_shp(file)
df = convert_from_geo_to_dataframe(geojson)
save_csv(df)'프로그래밍' 카테고리의 다른 글
| [mongoDB] mongo shell을 이용해서 collection 여러개 삭제하기 (0) | 2024.04.24 |
|---|---|
| [k8s] pod 내부에서 apt update (0) | 2024.01.22 |
| [SQL] (NOT)EXISTS 와 (NOT)IN 비교하기 (0) | 2023.04.17 |
| centos7 에 oracle 19c - silent 버전 설치하기 (2) | 2023.04.07 |
| sevice 로그 확인하기 (0) | 2023.04.07 |

